Framework
Oct. 2023: Code, data and interactive interface are released!
Applications that could benefit from automatic understanding of human-human conversations often come with challenges associated with private information in real-world data such as call center or clinical conversations. Working with protected data also increases costs of annotation, which limits technology development. To address these challenges, we propose DialGen, a human-in-the-loop semi-automated dialogue generation framework. DialGen uses a language model (ChatGPT) that can follow schema and style specifications to produce fluent conversational text, generating a complex conversation through iteratively generating subdialogues and using human feedback to correct inconsistencies or redirect the flow. In experiments on structured summarization of agent-client information gathering calls, framed as dialogue state tracking, we show that \dialgen data enables significant improvement in model performance.

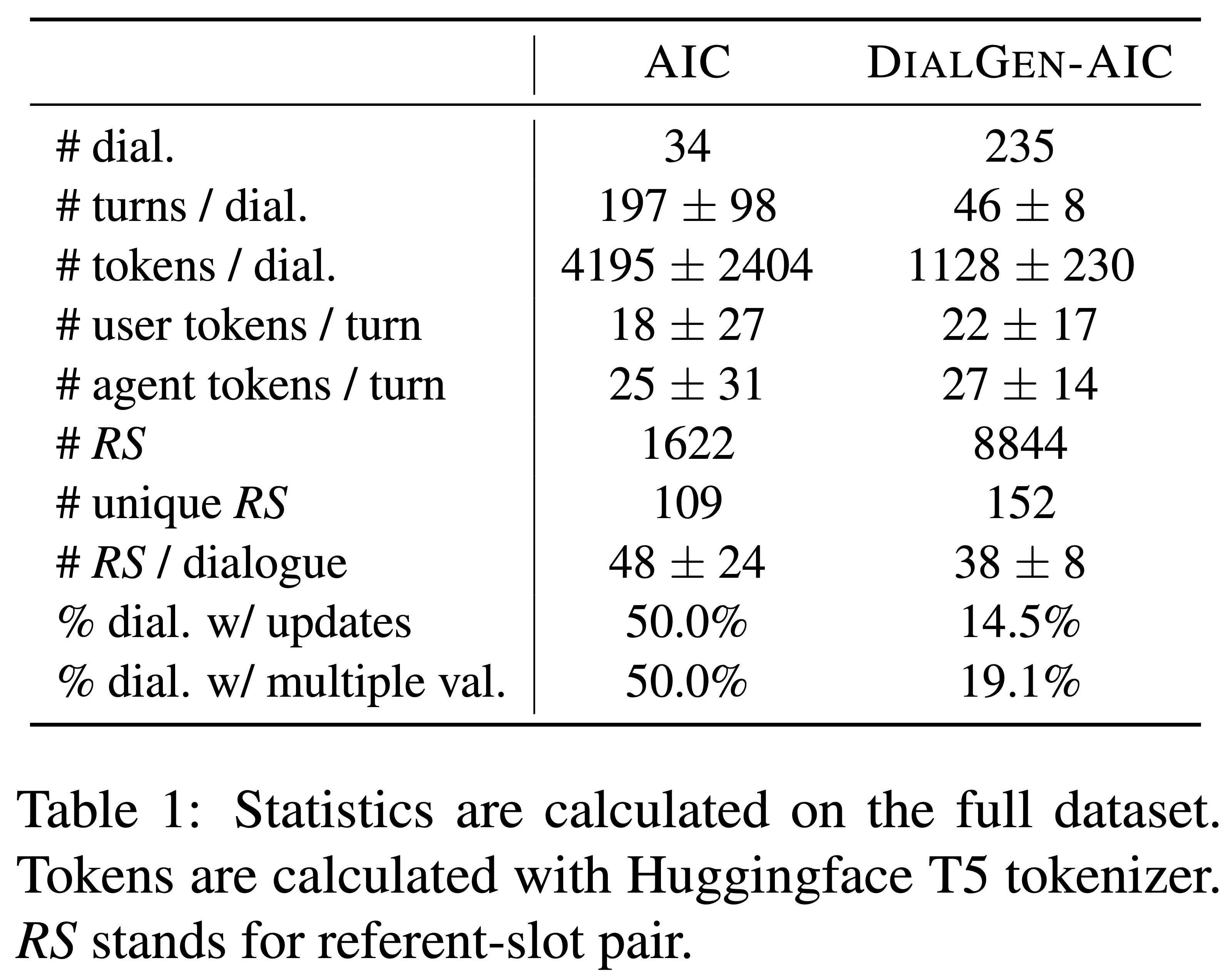

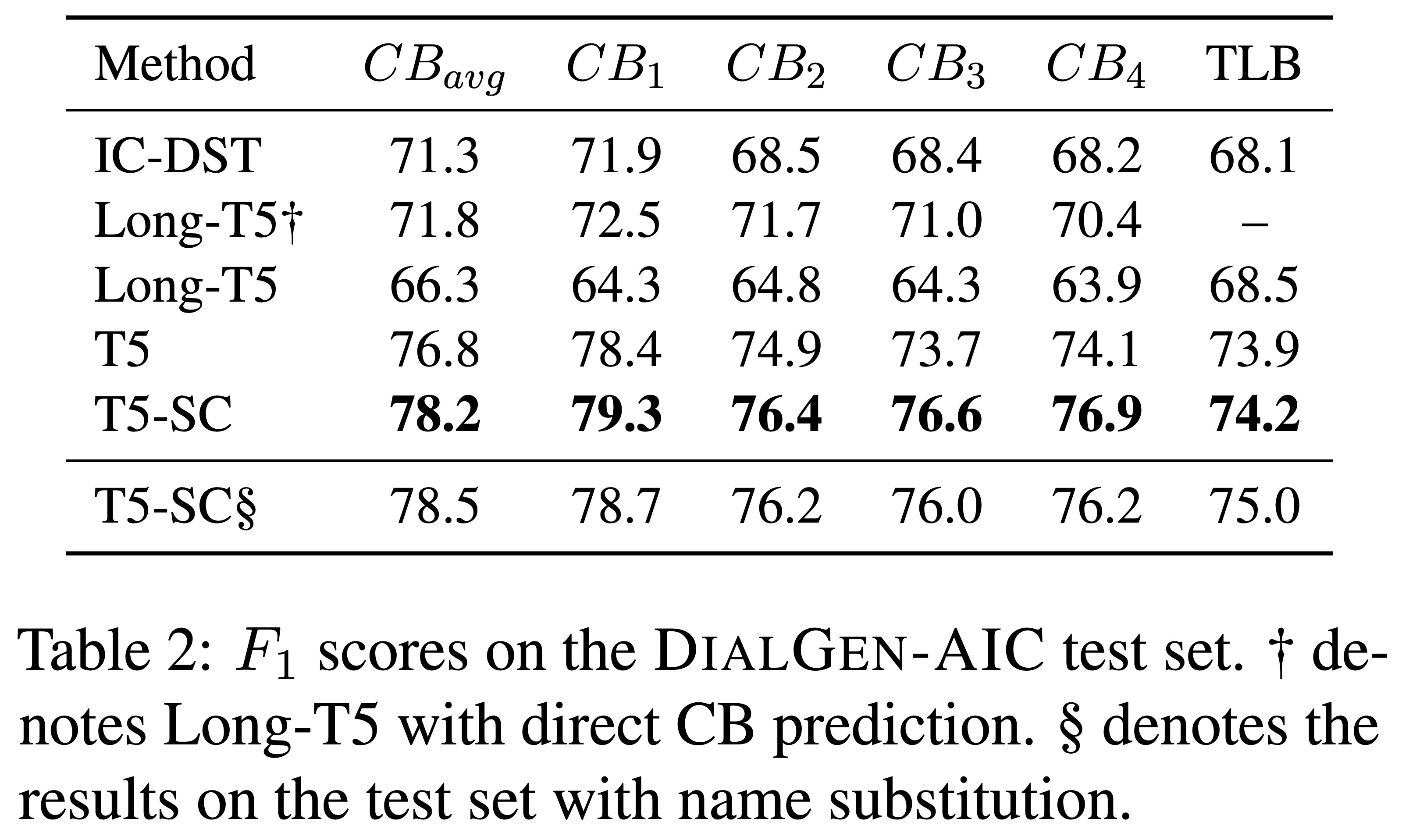
The results of experiments on DialGen-AIC with different learning strategies and T5 configurations are presented in Table 2. The performance of IC-DST is lower than all T5 variants, although this may be due to the difference in use of domain-specific prompts. However, given that our IC-DST implementation is based on the same ChatGPT model used for generating the synthetic dialogues, the low results suggest that human collaboration leads to data that is sufficiently different from ChatGPT text such that ChatGPT cannot easily address this task. Predicting CB directly requires the full history, which is only possible with Long-T5. With Long-T5, there is a benefit to predicting CB directly over TLB. However, optimizations needed to handle a longer history have tradeoffs that result in performance that is worse than the standard T5 model with TLB prediction for this task. The best result is obtained with T5 with state change (T5-SC), which updates values rather than simply adding them as new elements in a list.
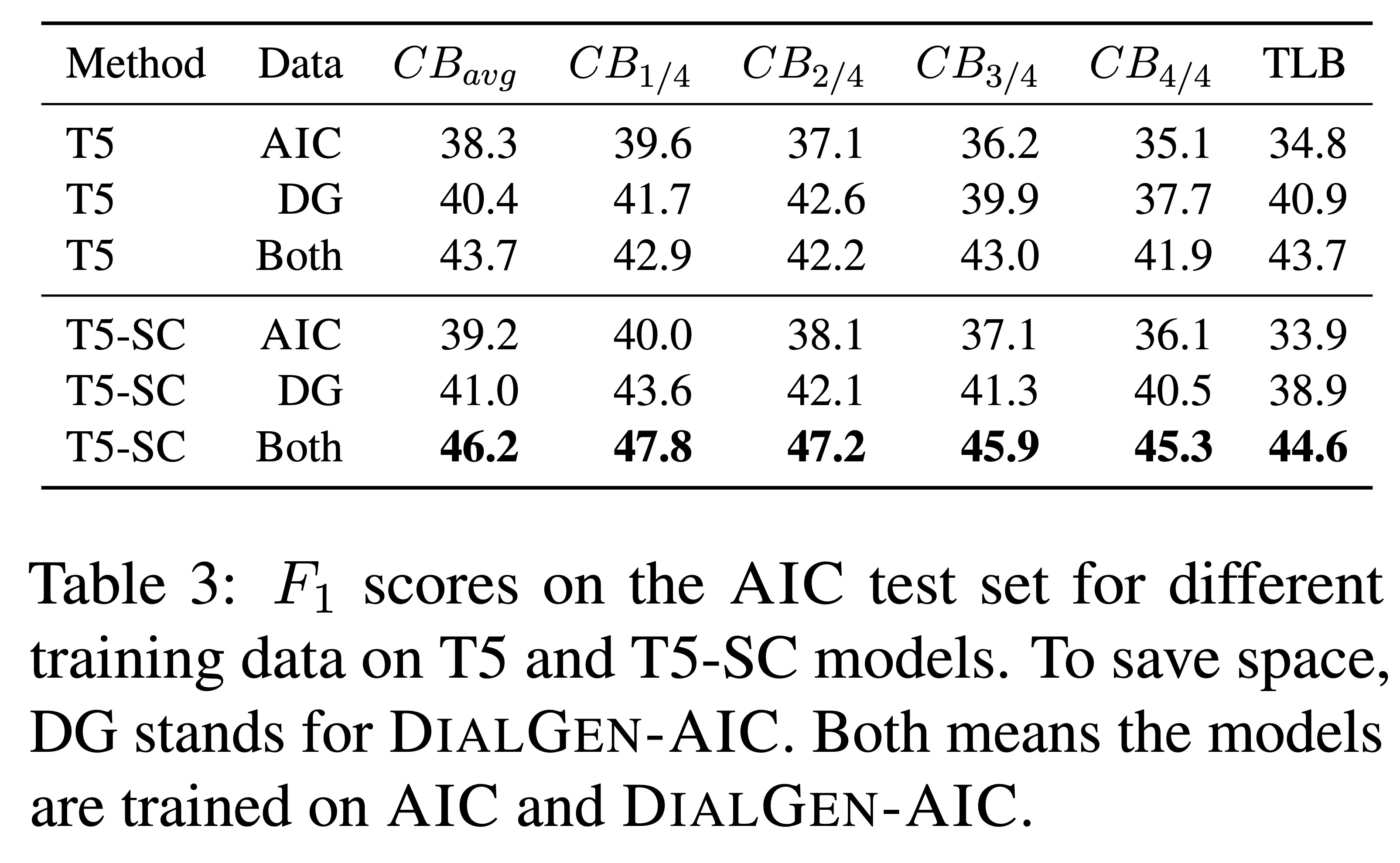
The two best models (T5 and T5-SC) are used in experiments on the AIC data. The F1 results for different training sources are given in Table 3. The performance for the model trained on the synthetic DialGen-AIC alone is better than with the small amount of AIC data, but the best results are obtained by model trained on both AIC and DialGen-AIC.
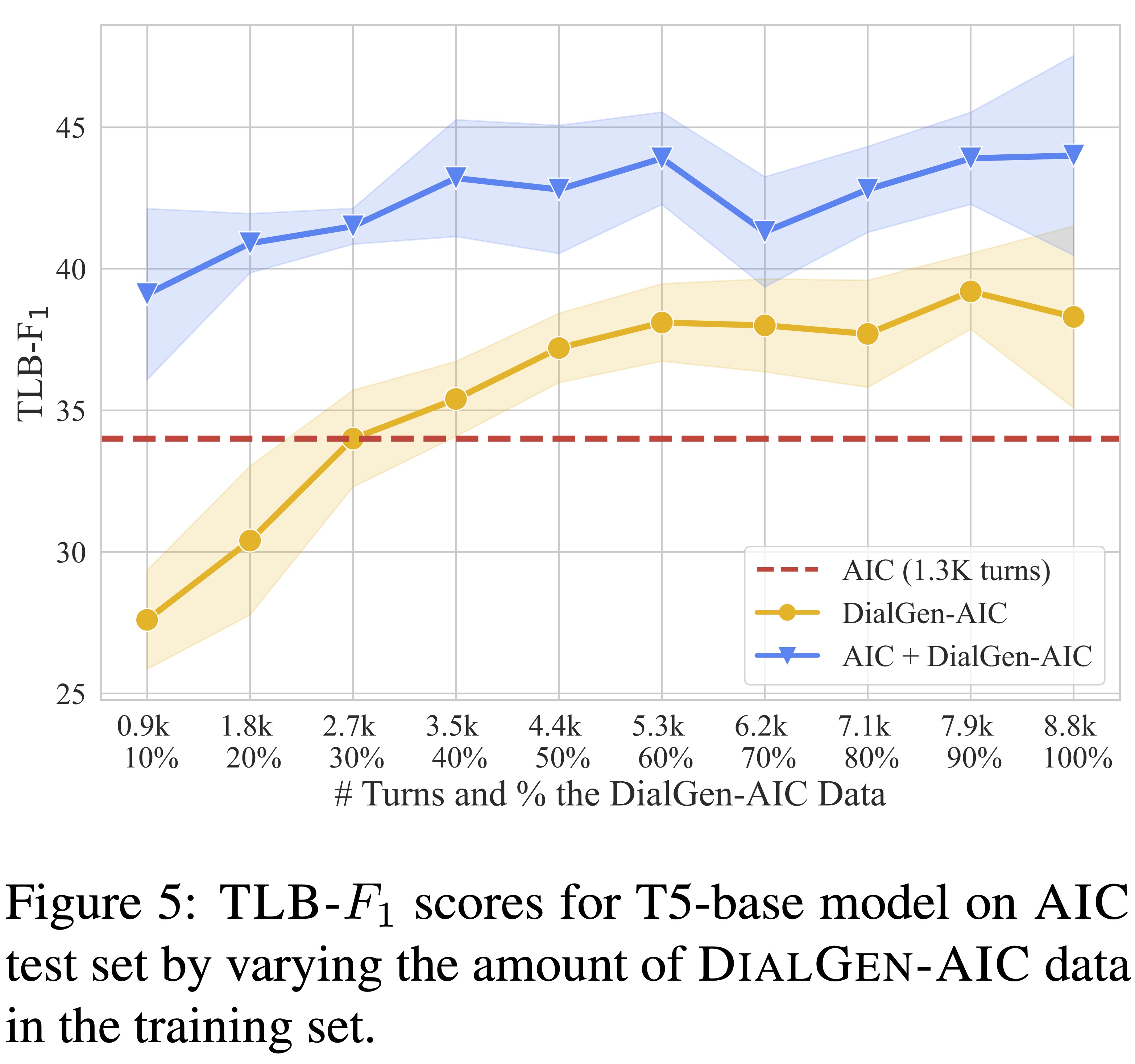
Table 5 shows that using 59 DialGen-AIC dialogues (approximately 2.7K turns) yields results similar to those obtained from the AIC training set, which consists of 1.3K turns in 7 dialogues. These results suggest that roughly 2.1 times as many turns of synthetic data is needed to match the performance of the real data, or 8.4 times as many synthetic dialogues since the synthetic dialogues are shorter. However, the synthetic data is more valuable in combination with real data, for which the benefit beyond the 97 dialogues (50%) is minimal. This suggests an opportunity for further improvement through strategic scenario sampling.
@misc{lu2023dialgen,
title={DIALGEN: Collaborative Human-LM Generated Dialogues for Improved Understanding of Human-Human Conversations},
author={Bo-Ru Lu and Nikita Haduong and Chia-Hsuan Lee and Zeqiu Wu and Hao Cheng and Paul Koester and Jean Utke and Tao Yu and Noah A. Smith and Mari Ostendorf},
year={2023},
eprint={2307.07047},
archivePrefix={arXiv},
primaryClass={cs.CL}
}